Sciling participa en el desarrollo de un proyecto Open Source para facilitar la vida de los modelos de ML
Recientemente, el equipo de Sciling empezó a participar en el desarrollo de un proyecto Open Source en colaboración con la empresa Modzy, centrada en acelerar la implementación, la integración y el liderazgo de la Inteligencia Artificial.
Ambas empresas buscan hacer posible la estandarización de los despliegues de los modelos de Machine Learning (ML) en producción, lo que significará un ahorro importante de tiempo y esfuerzo para los desarrolladores del ámbito MLOps. Crearán un servicio que sea capaz de estandarizar los despliegues, haciendo que un modelo de ML sea compatible con diferentes herramientas de despliegue.
Para ver las implicaciones de este proyecto y su relevancia, conviene que entremos en contexto y entendamos un poco lo complejo que resulta para cualquier desarrollador gestionar el despliegue de un modelo de ML con el uso de las herramientas disponibles hasta el momento.
Los modelos de Machine Learning
Vivimos en la era de la información, y eso nos sumerge inevitablemente en una inmensa cantidad de datos que circulan sin cesar a lo largo y ancho del universo digital. Procesar e interpretar toda esa información sería casi imposible sin la ayuda de la Inteligencia Artificial, específicamente los modelos de Machine Learning (ML) o aprendizaje automático.
Básicamente, podemos decir que cada proceso de aprendizaje automático, o Machine Learning, es un conjunto de operaciones diseñado para ejecutarse a fin de producir un modelo que, a su vez, no es más que una representación matemática de un proceso del mundo real. Dichos modelos se alimentan de datos para hallar patrones y hacer predicciones con mucha más eficacia que un ser humano.
El uso de aprendizaje automático en los sistemas de software o aplicaciones representa una revolución, ya que un modelo de ML es capaz de resolver problemas complejos con muchísima más rapidez y eficacia que los métodos tradicionales. De hecho, se han creado familias enteras de modelos de ML para diferentes usos, y muchos más están en proceso.
Por ejemplo, un tipo de modelo de ML son los modelos lineales, que utilizan patrones de datos numéricos para predecir las relaciones entre las variables de las proyecciones financieras. Otros son los modelos gráficos, que pueden expresar como diagramas una probabilidad como, por ejemplo, si un consumidor elegirá comprar un producto o no. Esto resulta sumamente útil para las industrias que se sirven de un catálogo online para vender, ya que podrán predecir el comportamiento de su público objetivo.
Poner un modelo de ML en producción no es tarea fácil
Ahora bien, no es lo mismo tener un modelo de ML preparado para inferir o clasificar datos cómodamente en un notebook de Jupyter, que tener que desplegar ese modelo en producción para que genere un valor auténtico. Aunque es cierto que el departamento de DevOps suele encargarse del despliegue del modelo, esto muchas veces sigue siendo responsabilidad del desarrollador del mismo.
Desplegar un modelo de ML significa entrenarlo, llevarlo al mundo real y ponerlo a disposición de softwares y aplicaciones con la clara intención de aprovechar al máximo el potencial del aprendizaje automático. Así, el modelo podrá alimentarse de datos específicos a fin de obtener predicciones o hallar patrones, que a su vez podrán usarse como entradas para otras aplicaciones.
En otras palabras, para aprovechar todo el potencial de los modelos de ML, es esencial desplegarlos o ponerlos en producción, disponibles al resto de aplicaciones que podrían usarlos. En este sentido, la realidad es que cerrar la brecha entre la construcción de modelos y su puesta en producción sigue siendo un verdadero desafío.
A este respecto, conviene mencionar los resultados obtenidos en el informe de Algorithmia 2020 State of Enterprise Machine Learning, en el que se hizo una encuesta entre unas 750 personas, incluyendo ejecutivos de empresas de tecnología y profesionales del ML. Los siguientes datos hablan por sí solos:
- El 50% de los encuestados afirmó que su empresa tarda entre una semana y tres meses para implementar un modelo de ML.
- El 18% de los encuestados respondió que a su empresa le lleva de tres meses a un año alcanzar el despliegue de un modelo de aprendizaje automático.
- Los principales desafíos de cara a implementar un modelo de ‘aprendizaje automático son el control de versiones, el escalado, la reproducibilidad del modelo y la alineación de todos los stakeholders involucrados’.
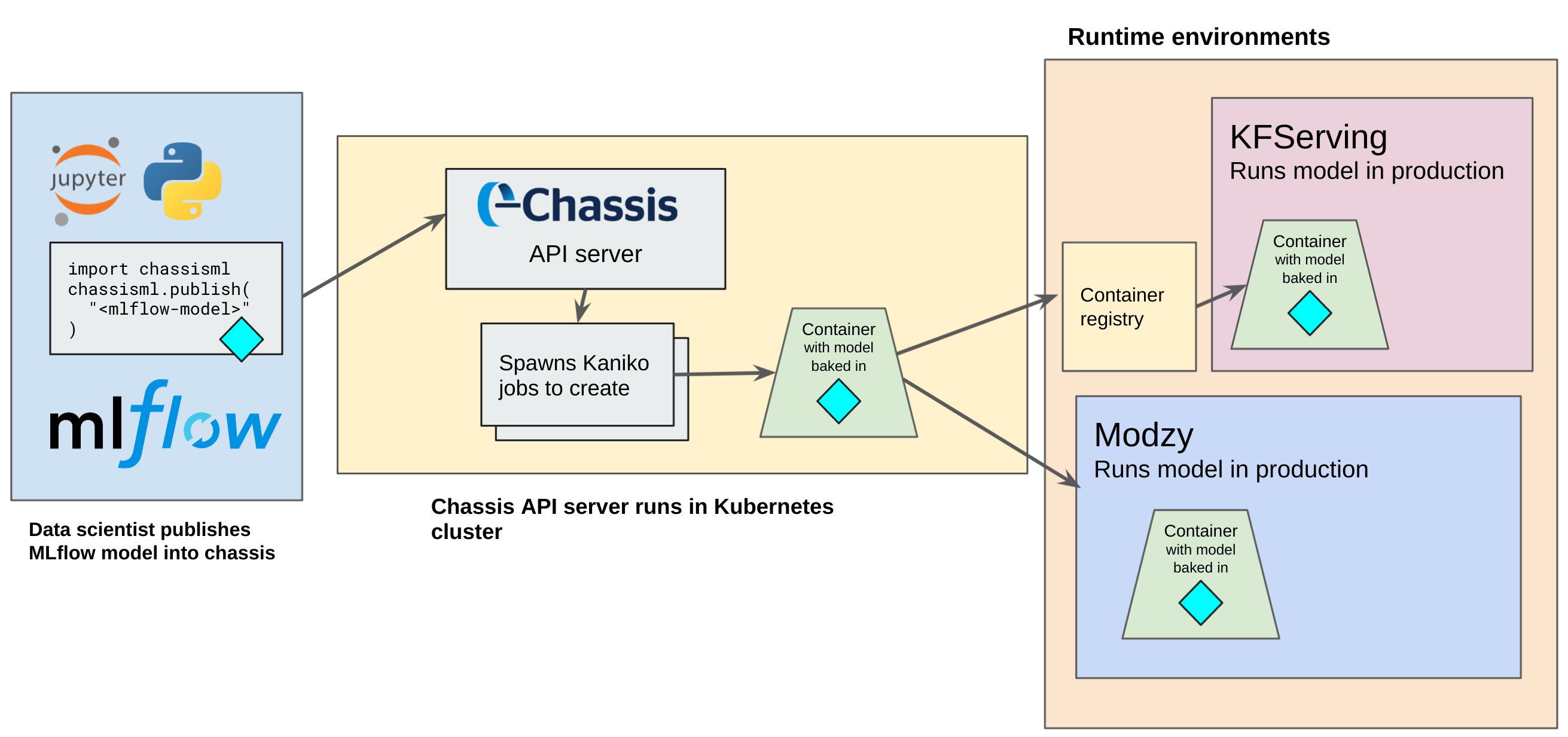
KFServing y Modzy, herramientas que facilitan el despliegue de modelos ML. Dos de las principales herramientas para el despliegue de modelos en producción son KFServing y la plataforma Modzy. Con KFServing, es posible crear una imagen desplegable de un modelo solo a partir de su fichero. Esto quiere decir que, después de entrenar el modelo, lo único que necesitas es definir un recurso de Kubernetes que utilice KFServing para desplegarlo y desarrollar todo el sistema de inferencia, predicción, etc.
Una vez desplegado el modelo de ML con KFServing, el sistema se encargará del resto del proceso, montará un API para hacer las predicciones, consultará el estado de salud del modelo y verificará el estado del modelo en materia de escalabilidad, red, etc. Otro servicio de este tipo es el que proporciona la empresa Modzy. En esta plataforma, simplemente hay que subir el modelo entrenado y el sistema se encarga de automatizar todo el despliegue.
Descripción y demo del sistema Chassis.ml
La estandarización de los despliegues de los modelos de ML en producción
Una de las razones por las que resulta tan difícil agilizar el proceso de despliegue de un modelo de ML es que, hasta la fecha, no hay un estándar para hacerlo.
Esto quiere decir que no existe un servicio que se encargue de hacer que un modelo sea compatible con las diferentes herramientas de despliegue disponibles hasta el momento.
Pues bien, la empresa Modzy se ha puesto en contacto con Sciling para colaborar en la creación de un servicio que sea capaz de estandarizar los despliegues, haciendo que un modelo de ML sea compatible con diferentes herramientas de despliegue.
De esta forma, solo es necesario desplegar el servicio en un clúster de Kubernetes y hacer una llamada a su API utilizando una librería de Python para crear una imagen Docker que es desplegable, hasta el momento, tanto en la plataforma de Modzy como en KFServing.
Este proyecto está publicado como Open Source, lo que hace posible que profesionales de ML y desarrolladores puedan contribuir con él. Toda la documentación de esta iniciativa y su avance están abiertos a la comunidad y pueden consultarse en https://chassis.ml. Con esto, Sciling contribuye una vez más de forma activa al mundo del ML apostando por proyectos Open Source para facilitar la vida de los desarrolladores.